
PHP操作Redis
基本指令
redis里有一些通用的操作,不管它是什么类型操作都是通用的,不过不管是做什么操作,都得先连接redis服务器,实例化redis对象
$redis = new Redis();
if (!$redis->connect('127.0.0.1', 6379)) {
trigger_error('Redis连接出错!!!', E_USER_ERROR);
} else {
echo '连接正常<br>';
}
获取所有的key(keys)
$data = $redis->keys('*');
dump($data);

判断键对应值的类型(type)
type()方法用户获取一个key对应值的类型,返回值(1:string, 2:set, 3:list, 4:zset, 5:hash 6:未知)
$type = $redis->type('user');
dump($type);
删除缓存项(del)
$redis->del('待删除的key')
设置有效期(expire,expireAt)
需要在设置好了缓存项后,在设置有效期
expire()方法是设置某个时间段后过期,`expireAt()方法是在某个时间点(时间戳)过期失效
//expire用法示例
//expire()方法第二个参数的单位是秒(s),表示多少秒之后过期
$redis->expire('user', 3600);
//expire用法示例
$redis->expireAt('user', strtotime('2020-08-15 00:00:00'));
如果想精确到毫秒的话,redis还提供了pExpire()、pExpireAt()方法可供使用
获取有效期(ttl)
ttl()方法可以获取某个键的剩余有效期
$redis->ttl('key'); //获取剩余有效期,单位:秒(s)
$redis->pttl('key'); //获取剩余有效期,单位:毫秒(ms)
检测缓存项是否存在(exists)
exists()方法用于检测某个key是否存在
$redis->set('age', 25);
if ($redis->exists('age')) {
echo '存在';
} else {
echo '不存在';
}
查看当前数据库key的数量(dbSize)
$dbSize = $redis->dbSize();
echo $dbSize;
清空当前数据库(flushDB)
$isFlushed = $redis->flushDB();
var_dump($isFlushed);
清空所有数据库(flushAll)
会清空所有库的数据,默认是0~15这16个数据库
$isFlushed = $redis->flushAll();
var_dump($isFlushed);
字符串(string)类型
string是Redis最基本的类型,你可以理解成Memcached一模一样的类型,一个key对应一个value。
string类型是二进制安全的。这意味着Redis的string可以包含任何数据。比如JPG图片或者序列化的对象。
一个Redis中字符串value最多可以是512M
设置(set)
仅仅支持字符串操作,不支持内置数据编码功能。如果需要存储PHP的非字符串类型,需要提前手动序列化,获取时再反序列化。
$user = [
'name' => 'bashlog',
'age' => 26,
'email' => 'xxxx@gmail.com'
];
//将$user数组序列化成json字符串
$user = json_encode($user);
$redis->set('user', $user);
$data = $redis->get('user');
//拿到序列化后的字符串,再反序列化成PHP数组
$data = json_decode($data, true);
var_dump($data);
setnx()方法是只有在key不存在时设置key的值,
设置并指定过期时间(setex)
设置键的同时,设置过期时间(时间单位是秒)
$redis->setex('hobby', 60, 'fishing');
获取(get)
$redis->set('name', 'bashlog'); //设置
$name = $redis->get('name'); //获取
var_dump($name);
增加(incr, incrBy)
incr()、incrBy()都是操作数字,对数字进行增加的操作,incr是执行原子加1操作,incrBy是增加指定的数
$redis->set('age', 10);
$redis->incr('age'); //等于$age++
$redis->incrBy('age', 5); // 等于$age = $age + 5
原子性
所谓原子操作是指不会被线程调度机制打断的操作:这种操作一旦开始,就一直运行到结束,中阿金不会有任何context witch(切换到另一个线程).
(1)在单线程中,能够在单条指令中完成的操作都可以认为是“原子操作”,因为中断只能发生于指令之间。
(2)在多线程中,不能被其它进程(线程)打算的操作叫原子操作。
Redis单命令的原子性主要得益于Redis的单线程
减少(decr, decrBy)
decr()和decrBy()方法是对数字进行减的操作,和incr正好相反
$redis->set('age', 10);
$redis->decr('age'); //等于$age--
$redis->decrBy('age', 5); // 等于$age = $age - 5
追加(append)
append()表示往字符串后面追加元素,返回值是字符串的总长度
示例:在'hello'后面追加' world'
$redis->set('respect', 'hello');
$length = $redis->append('respect', ' world');
var_dump($length);
获取长度(strLen)
strLen()方法可以获取字符串的长度
$redis->set('respect', 'hello');
$length = $redis->strlen('respect');
var_dump($length);
字符串截取(getRange)
getRange()方法可以用来截取字符串的部分内容,第二个参数是下标索引的开始位置,第三个参数是下标索引的结束位置(不是要截取的长度),
$redis->set('ID', '411521199809151234');
$subStr = $redis->getRange('ID', 0, 5);
var_dump($subStr);
此外,字符串(string)类型还有mget()、mset()、msetnx()、getSet()等方法.....
列表(list)类型
Redis列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)
一个列表最多可以包含232 - 1 个元素 (4294967295, 每个列表超过40亿个元素)。
将元素压入链表(lPush)
可以使用lPush()方法将数据从左侧压入列表
$redis->lPush('list', 'v1');
$redis->lPush('list', 'v2');
$redis->lPush('list', 'v2', 'v3');
可以通过Redis Desktop Manager查看插入情况
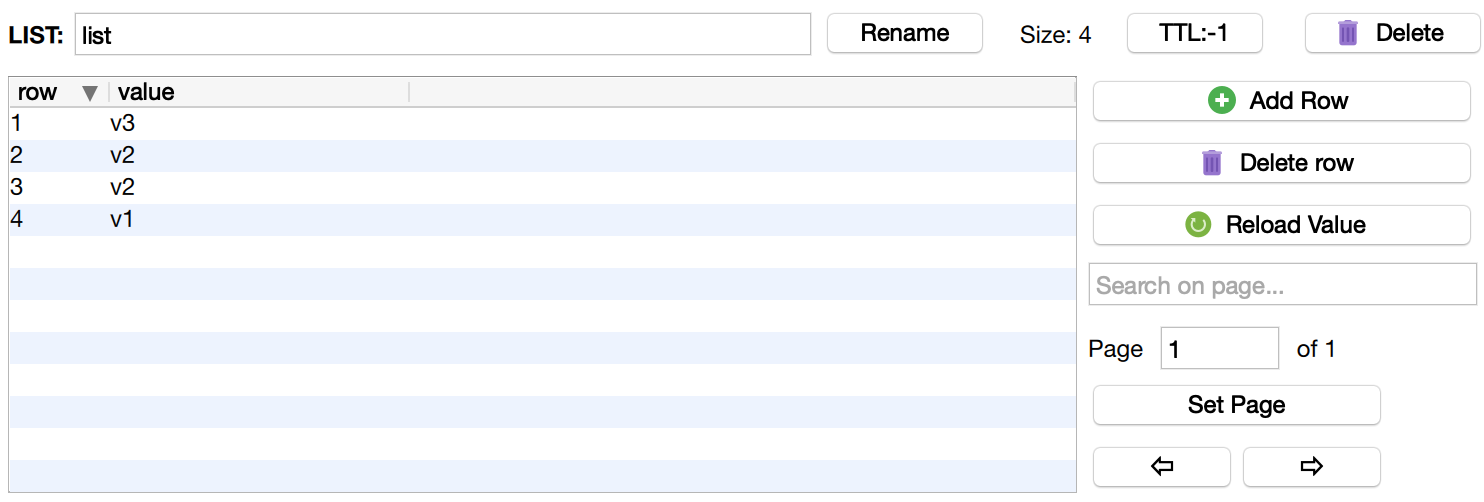
也可以从右侧压入列表,对应的方式是rPush()
在某个位置插入新元素(lInsert)
位置的判断,是根据相对的参考元素判断
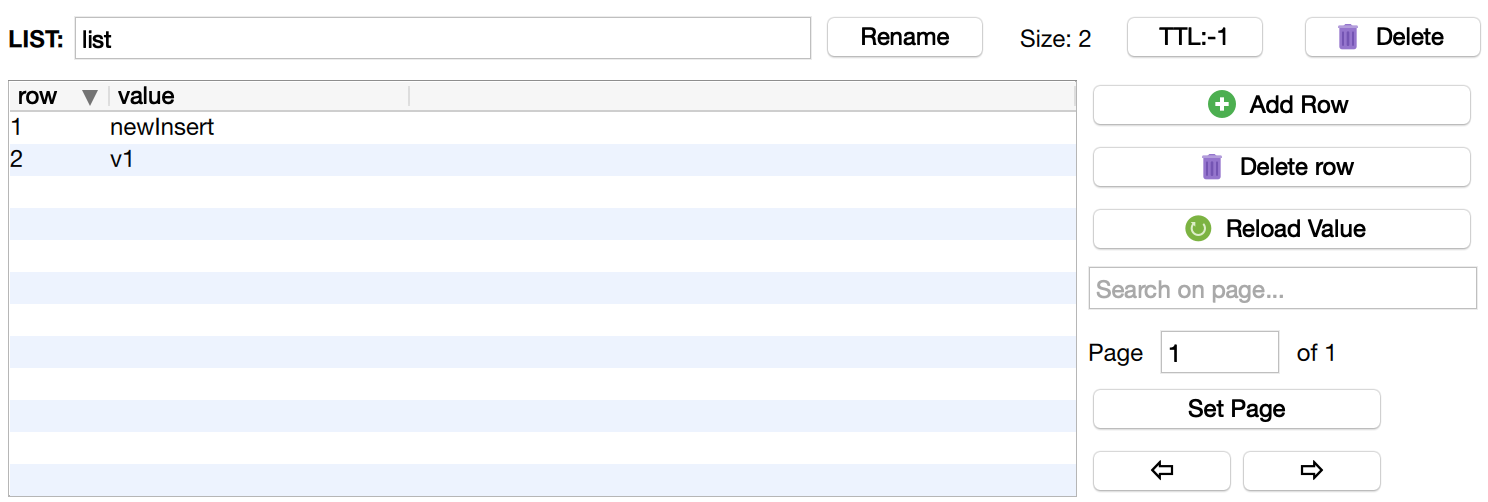
我们在之前的list链表往里插入数据
$redis->lInsert('list', Redis::BEFORE, 'v2', 'newInsert');
插入结果如下, 虽然有两个'v2',但是也只会在第一个'v2'前插入数据
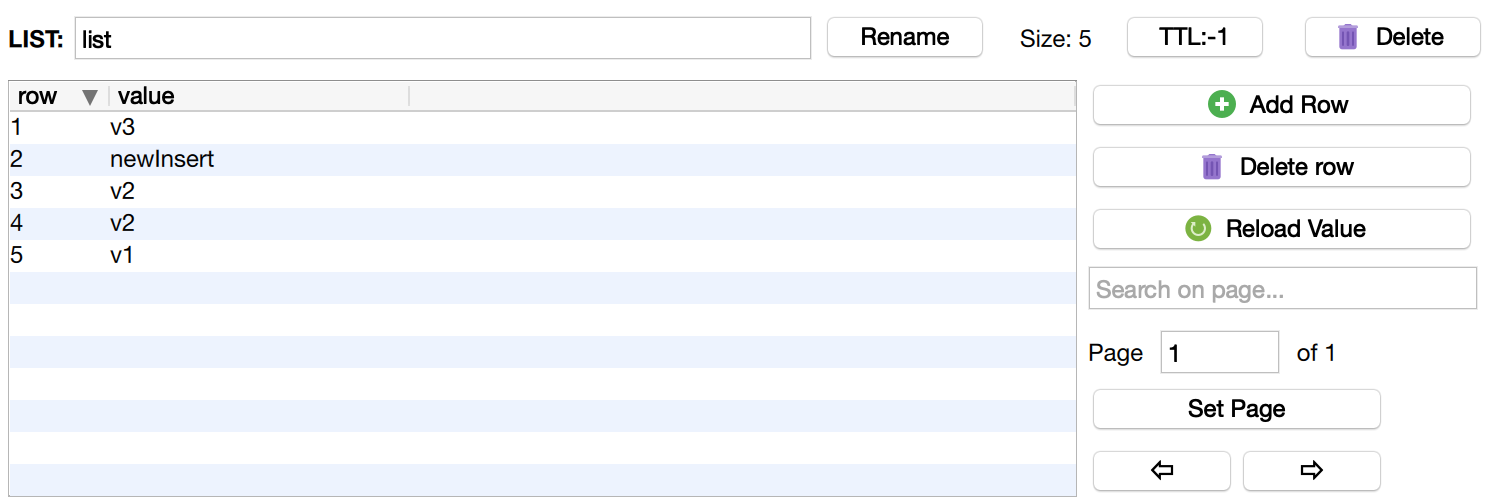
也可以在一个元素后面插入,使用Redis::AFTER
$redis->lInsert('list', Redis::AFTER, 'v2', 'newAfterInsert');
设置某个元素的值(lSet)
lSet()方法可以通过下标修改链表元素的值,下标是从0开始。
# 将list链表中的第一个元素v3改为newV3
$redis->lSet('list', 0, 'newV3');
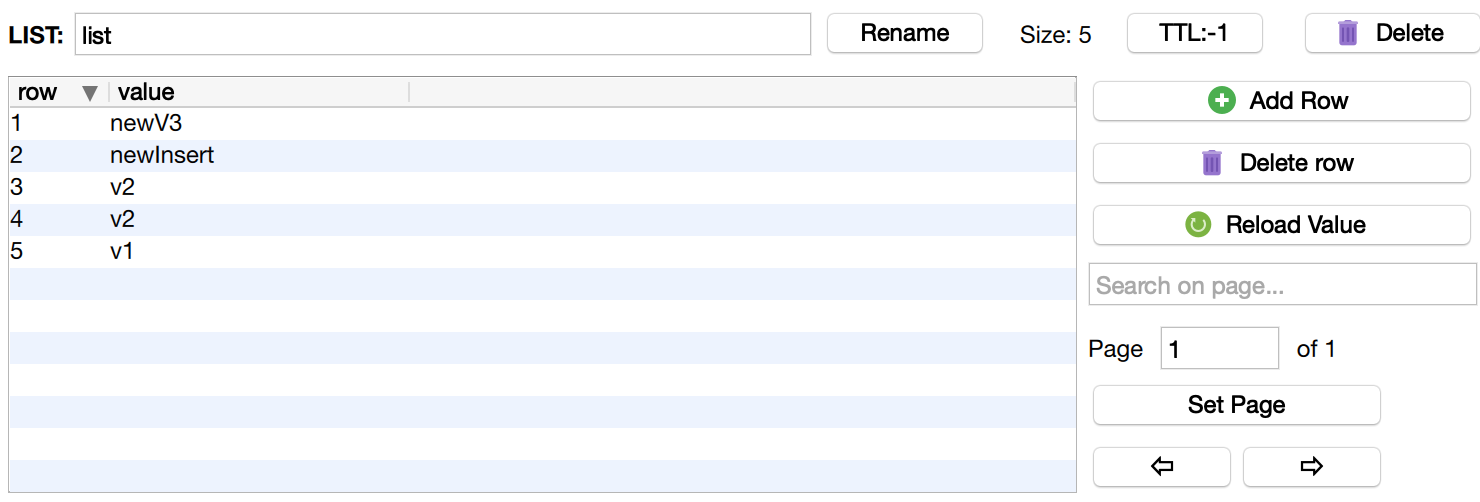
获取列表元素个数(lLen)
llen()方法可以获取元素个数
$length = $redis->lLen('list');
echo $length;
获取下标对应的元素(lIndex)
$val = $redis->lIndex('list', 1);
echo $val;
获取某个选定范围元素集(lRange)
lRange()方法支持通过起止下标来获取列表某个范围内的元素集
$arr = $redis->lRange('list', 0, 1); //前两个元素
$arr = $redis->lRange('list', 0, -1); //全部元素
$arr = $redis->lRange('list', -2, -1); //后两个元素
var_dump($arr);
从列表左侧弹出数据(lPop)
lPop()方法将数据从列表左侧弹出,返回弹出的元素,数据元素在list中消失。
$val = $redis->lPop('list');
echo $val;
查看list列表可以发现,原本第一个元素'newVe3'已经不在list中了
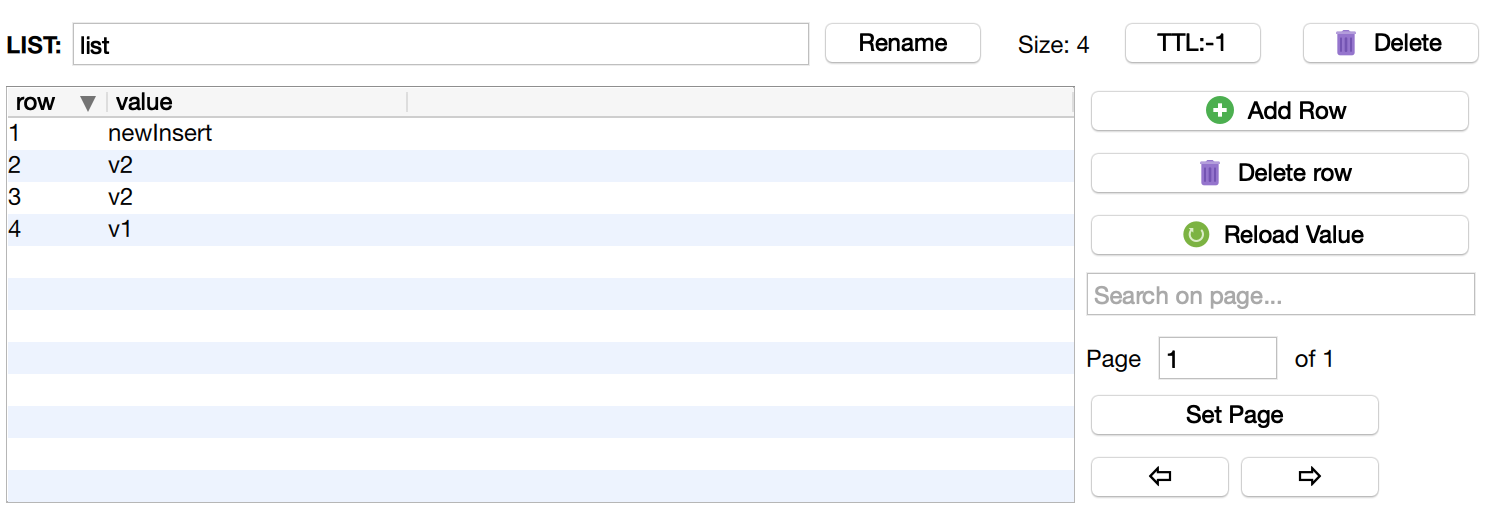
如果想从右侧弹出数据,可以使用rPop()方法
根据值移除元素(lRem)
可以使用lRem()方法根据值来移除元素,并且可以指定要移除的元素个数,因为list中可能出现重复的元素
$res = $redis->lRem('list', 'v2', 2);
echo $res;
集合(set)类型
Redis set对外提供的功能与list类似是一个列表的功能,特殊之处在于set是可以自动排重的,当你需要存储一个列表数据,又不希望出现重复数据,set是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的接口,这是也是list所不能提供了。
Redis的Set是string类型的无需集合。它底层其实是一个value为null的hash表,所以添加、删除、查找的复杂度都是O(1)。
集合数据的特征:
- 元素不能重复,保持唯一性
- 元素无序,不能使用索引(下标)操作
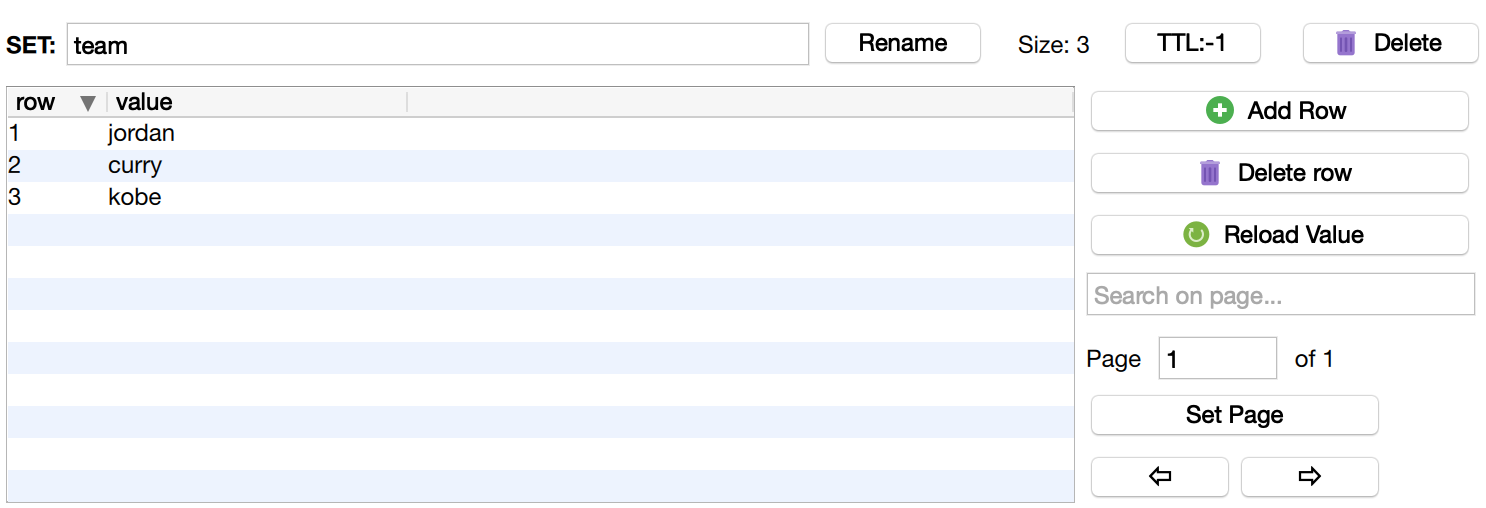
添加元素到集合(sAdd)
$redis->sAdd('team', 'kobe');
$redis->sAdd('team', 'jordan');
$redis->sAdd('team', 'curry');
$redis->sAdd('team', 'kobe');//由于kobe已经被添加到team集合中,所以重复添加是无效的
随机获取一个元素(sPop)
无序性,是随机的
sPop()方法是从集合中随机取出元素的,它有两个参数,第二个参数表示要取出多少个数据,默认是1
$redis->sPop('team');
删除集合里指定的值(sRem)
$redis->sAdd('k', 'v1', 'v2', 'v3');
$redis->sRem('k', 'v2', 'v3');
$leftData = $redis->sMembers('k');
dump($leftData);
遍历集合(sScan)
//不使用迭代器,匹配所有的元素,进行遍历
$iterator = null;
$elements = $redis->sScan('team', $iterator, '*');
foreach ($elements as $element) {
echo $element, '<br>';
}
获取所有成员(sMembers)
$members = $redis->sMembers('team');
var_dump($members);
获取集合元素个数(sCard)
获取集合中元素个数
$count = $redis->sCard('team');
echo $count;
并集(sUnion),差集(sDiff),交集(sInter)
PHPRedis提供了一些对集合的相互操作
$redis->sAdd('setA', 'a', 'b', 'c', 'd');
$redis->sAdd('setB', 'a', 'd', 'e', 'f');
$union = $redis->sUnion('setA', 'setB');
$diff = $redis->sDiff('setA', 'setB');
$inter = $redis->sInter('setA', 'setB');
dump($union);
dump($diff);
dump($inter);

有序集合(zset)类型
Redis 有序集合和集合一样也是string类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
有序集合的成员是唯一的,但分数(score)却可以重复。
集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。 集合中最大的成员数为 232 - 1 (4294967295, 每个集合可存储40多亿个成员)。

处理元素时,也要加上score的处理
添加元素(zAdd)
添加6个元素(1~6),分值都是0
$redis->zAdd('zSet', 0, 1);
$redis->zAdd('zSet', 0, 2);
$redis->zAdd('zSet', 0, 3);
$redis->zAdd('zSet', 0, 4);
$redis->zAdd('zSet', 0, 5);
$redis->zAdd('zSet', 0, 6);

元素分值增减(zIncrBy)
分值可以为负数,表示递减
$redis->zIncrBy('zSet', mt_rand(0, 100), 1);
$redis->zIncrBy('zSet', mt_rand(0, 100), 2);
$redis->zIncrBy('zSet', mt_rand(0, 100), 3);
$redis->zIncrBy('zSet', mt_rand(0, 100), 4);
$redis->zIncrBy('zSet', mt_rand(0, 100), 5);
$redis->zIncrBy('zSet', mt_rand(0, 100), 6);

获取根据score排序后的数据段(zRange,zRevRange)
根据分值排序后的,升序和降序的列表获取
//获取排行榜
//获取分值(点击率)前三的文章ID列表
$lists = $redis->zRevRange('zSet', 0, 2, true);
dump($lists);

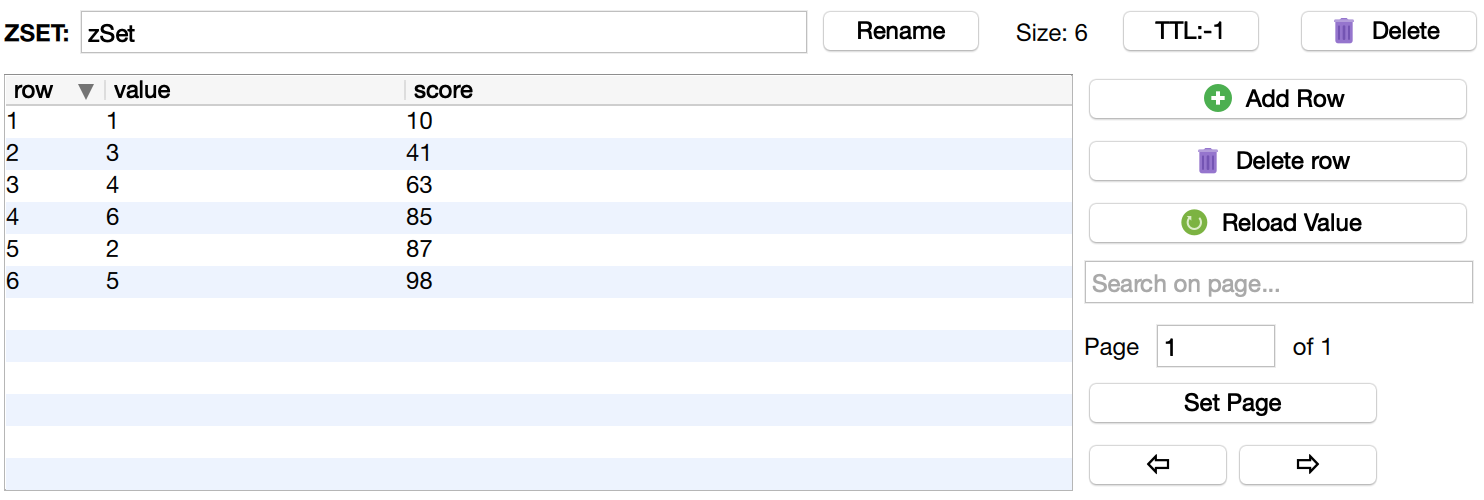
获取score过滤后排序的数据段(zRangeByScore,zRevRangeByScore)
根据分值过滤之后的列表
需要提供分值区间
$lists = $redis->zRangeByScore('zSet', 40, 90, ['withscores' => true]);
dump($lists);
原始数据如下图

获取元素个数(zCard)
$count = $redis->zCard('zSet');
echo $count;
获取区间内的元素个数(zCount)
获取分值在[50,90]的元素的数量
$count = $redis->zCount('zSet', 50, 90);
echo $count;
获取元素的score(zScore)
获取元素分值
$score = $redis->zScore('zSet', 6);
echo $score;
获取某个元素在集合中的排名(zRank)
zRank()方法是返回元素在集合中的排名情况,从0开始。
$order = $redis->zRank('zSet', 56);
删除元素(zRem)
zRem()方法支持通过元素的值来删除元素
//通过元素值来删除元素
$redis->zRem('zSet', 6);
根据排名来删除(zRemRangeByRank)
//按照升序排序删除第一个和第二个元素
$redis->zRemRangeByRank('zSet', 0, 1);
根据区间来删除(zRemRangeByScore)
//删除score在[40, 70]之间的元素
$redis->zRemRangeByScore('zSet', 40, 70);
哈希(hash)类型
Redis hash 是一个 string 类型的 field(字段) 和 value(值) 的映射表,hash 特别适合用于存储对象。
Redis 中每个 hash 可以存储 232 - 1 键值对(40多亿)。
当前服务器一般都是将用户登录信息保存到Redis中,这里存储用户登录信息就比较适合用hash表。hash表比string更合适,如果我们选择使用string类型来存储用户的信息的时候,我们每次存储的时候就得先序列化(json_encode()、serialize())成字符串才能存储redis,
从redis拿到用户信息后又得反序列化(json_decode()、unserialize())成数组或对象,这样开销比较大。如果使用hash的话我们通过key(用户ID)+field(属性标签)就可以操作对应属性数据了,既不需要重复存储数据,也不会带来序列化和并发修改控制的问题。
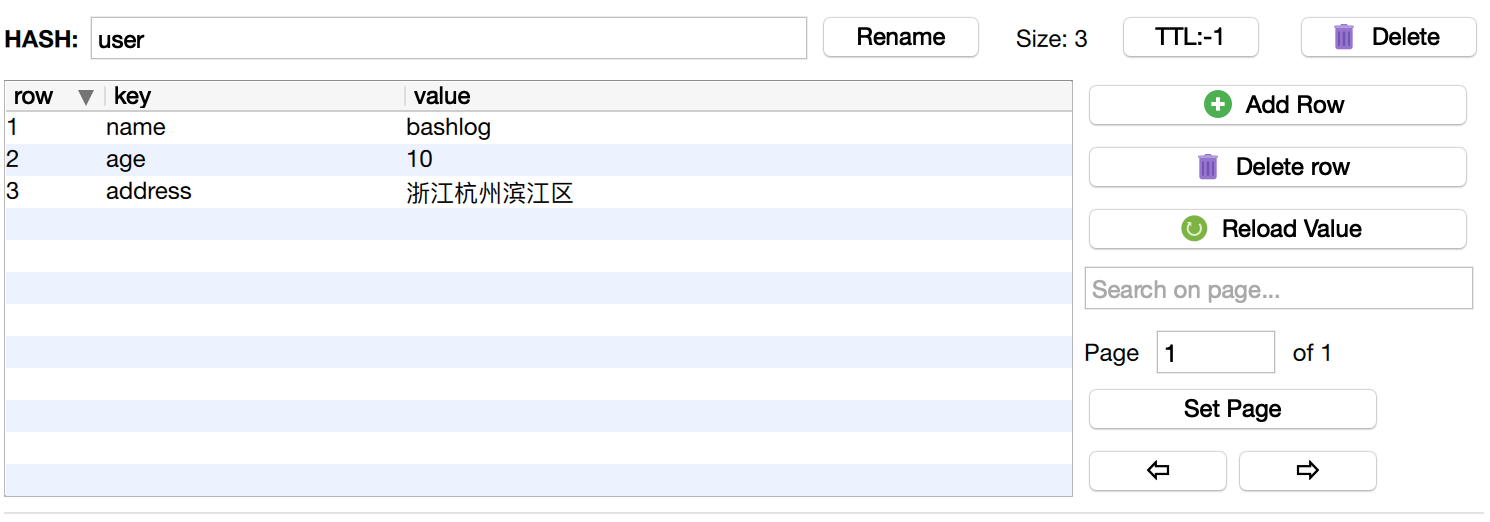
设置(hSet)
$redis->hSet('user', 'name', 'bashlog');
$redis->hSet('user', 'age', 10);
$redis->hSet('user', 'address', '浙江杭州滨江区');
上面的操作等价于PHP中的
$user['name'] = 'bashlog';
$user['age'] = 10;
$user['address'] = '浙江杭州滨江'
批量设置(hMset)
上面使用hSet设置的方式需要多次设置,不太方便,Redis提供了批量设置的方法hMset(),我们可以用这个方法将用户登录信息一次性保存到redis中
$u1 = [
'id'=> 1,
'name' => 'itbsl',
'age' => 25,
'email' => 'itbsl@gmail.com',
'address' => '北京朝阳区大望路'
];
$redis->hMSet('user:'.$u1['id'], $u1);
$u2 = [
'id' => 2,
'name' => 'bashlog',
'age' => 26,
'email' => 'bash@gmail.com',
'address' => '北京市海淀区西二旗'
];
$redis->hMSet('user:'.$u2['id'], $u2);

为什么要给存储的数据加一个前缀呢,比如说上面示例的user前缀?
因为我们在redis一般需要存储很多业务类型的数据,比如用户登录信息、验证码信息,我们都是以用户唯一标识信息(如id,手机号)作为key,如果不加前缀就会导致多个业务类型的数据就存到一起了,这是不合理也不应该的。所以我们可以以业务名称作为前缀然后配合上用户唯一标识即前缀:唯一标识作为key,中间是用冒号:分隔,这样就可以把数据按照业务类型分开,这也是业界通用的做法,比如我们php的session存储默认也是一PHPREDIS_SESSION作为前缀,官方都是这么做了,我们还有什么理由不这样做呢。
获取(hGet)
下面的操作等价于PHP中的$name = $user['name'];
$name = $redis->hGet('user', 'name');
echo $name;
获取全部元素(hGetAll)
$user = $redis->hGetAll('user');
dump($user);

删除某个元素(hDle)
$res = $redis->hDel('user', 'address');
var_dump($res);

判断元素是否存在(hExists)
$isExistent = $redis->hExists('user', 'address');
var_dump($isExistent);
获取长度(hLen)
$hLen = $redis->hLen('user');
var_dump($hLen);
如果该文章对您有帮助,请您点个推荐,感谢。

